
8 minute read
GIT flow è un flusso di sviluppo, ideato da Vincent Driessen, che descrive un modello di diramazione, (branching), ben preciso costruito intorno al concetto di release software.
Questo flusso è concepito per sfruttare al meglio le potenzialità del software di versionamento GIT, ma affinità concettuali possono essere utili anche per la gestione del lavoro con altri software dediti alla medesima funzionalità.
Il flusso descritto in GIT flow è finalizzato a mantenere una storia implementativa pulita, dove un rilascio comunica a tutti gli utilizzatori la presenza di una nuova versione del prodotto, definita da un determinato changelog composto da nuove caratteristiche e correzioni.
I vantaggi derivanti da questo approccio al versionamento (software versioning), sono anzitutto quello di tenere una storia pulita e leggibile, il che faciliterà la vita a chi decide di usare il nostro software, ma anche quello di poter concentrare e diversificare gli sforzi del team di sviluppo sulle particolari fasi: implementazione, correzione, pulizia, rilascio, concedendo a ciascuna di esse determinati spazi all’interno del repository e determinate tempistiche all’interno del flusso.
In questo articolo descriveremo git flow e uniremo l’adozione di questo flusso a quello di una strategia di versionamento semantico (semantic versioning) così come proposto e descritta da Tom Preston-Werner.
Come vedremo in seguito il punto di incontro fra git e il versionamento semantico ha la sua chiave di volta nella creazione di tag appropriate sulle commit dei nostri rami o tagging.
Inoltre è bene tenere a mente che diversi software di gestione delle dipendenze basano il proprio flusso operativo sul presupposto una strategia di versionamento semantico simile a quella che andremo a descrivere, come ad esempio composer.
Branch storici
Anzitutto questo modello di workflow prevede la presenza di ben due master branch, “dev” (o “develop”) utilizzato per lo sviluppo, ed il buon vecchio “master” per i rilasci ufficiali.
Questi due branch assolvono il compito di “historical branch”, cioè essi devono detenere la storia pulita del progetto, a prescindere dagli sviluppi di nuove feature e hotfix, che altrimenti confluirebbero senza filtri sul ramo principale, rendendo meno comprensibile la storia del progetto e quindi più difficoltose operazioni di reversione (revert) a stati precedenti.
Branch di funzionalità
Un branch di funzionalità, ovvero un “feature branch”, aggiunge una nuova funzionalità (feature) al software. Nel modello proposto dal GIT flow, questi branch devono sempre essere derivati dal branch “develop” e rappresentano una feature, ovvero una nuova funzionalità che si intende aggiungere al software.
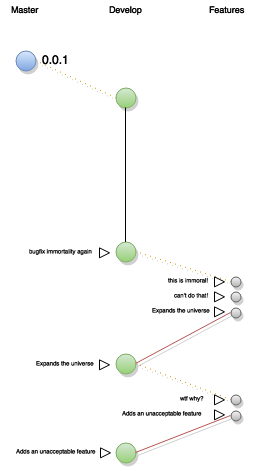
Questo branch conterrà tutti i pezzi di storia, le commit, relative alla funzionalità implementata.
Durante lo sviluppo di questi rami non è strettamente necessario mantenere una storia delle versioni pulite o usare particolari nomenclature per le varie commit (pratica che comunque potrebbe avere i suoi vantaggi come vedremo nell’ultimo paragrafo), in quanto prima di riportare il branch su develop, “appiattiremo” la storia del branch attraverso un’operazione di squash delle commit.
In questo modo la storia del branch di sviluppo risulterà pulita, con una sola commit, che conterrà solo l’informazione relativa all’aggiunta della nuova funzionalità.
Dopo averlo riportato su develop, è possibile rimuovere il feature branch dal repository:
$> git branch -D feat-nomedelfeaturebranch
In base alle dimensioni del team è possibile mantenere più feature branch contemporaneamente, a patto di riportarli correttamente e in tempi auspicabilmente brevi sul branch di sviluppo. Di norma un singolo sviluppatore si concentra sul rilascio di una feature per volta.
Branch di rilascio
Quando il ramo di sviluppo (develop) contiene abbastanza feature per un rilascio (o in base a qualsiasi altro tipo di scadenza prefissata), da questi viene derivato un nuovo branch detto di rilascio, o release branch.
È buona norma distinguere questi rami con un nome significativo e consistente, ad esempio possono tutti iniziare con il prefisso “release-”.
A questo punto dello sviluppo non possono essere più aggiunte feature e le uniche aggiunte possibili possono essere quelle di bug fixing e documentazione.
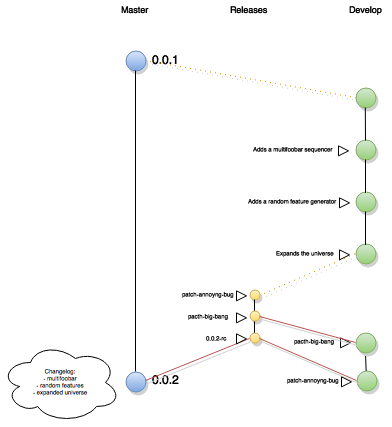
Il team si concentrerà sull’obiettivo di riportare su master la prossima release quindi non verranno creati altri branch di funzionalità in quanto in questa fase l’obiettivo principale è quello di rilasciare.
Quando il ramo di rilascio sarà maturo e testato, a questo punto verrà eseguita l’operazione di merge sul branch “master”, contrassegnandola con un’opportuna tag, che ne indichi il versionamento.
Come per il feature branch, la storia completa dalla nascita alla maturazione di questo ramo dovrebbe essere trasparente per i branch storici, quindi anche qui andremo ad operare un’operazione di squash.
Anche durante il ciclo di vita di questi rami, è buona pratica usare nomenclature particolari per i tag delle commit, ma non indispensabile: vedremo questo concetto più avanti nell’ultimo paragrafo.
Allo stesso modo il branch di rilascio verrà eseguita indietro anche sul branch “develop”, tralasciando l’aggiunta dei tag di versione.
Una volta mergiato con i branch storici, il branch di release non ha più motivo di esistere e sarebbe opportuno cancellarlo.
Branch di manutenzione
Una migliore organizzazione dei rilasci non scongiura sicuramente l’occorrenza di problemi da risolvere con estrema urgenza. In questo caso, e solo in questo caso, è possibile derivare (avviare un fork) direttamente da master un branch di manutenzione, contenente la fix necessaria a risolvere il problema insorto.
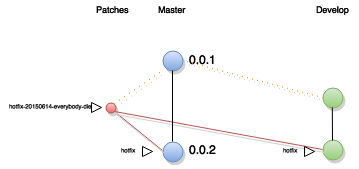
È buona norma inoltre distinguere questi branch con un nome significativo e consistente, ad esempio possono tutti iniziare con il prefisso “hotfix-”.
Tale branch sarà ovviamente riportato su “master” il più presto possibile, ed in seguito anche su “develop” per mantenere la situazione dei due branch storici allineata.
Come nel caso dei branch di rilascio, qundo un branch di manutenzione viene riportato su master, il tag di master verrà contrassegnato appropriatamente.
Versionamento semantico
Il versionamento semantico (semantic versioning) è un semplice schema di denominazione dei rilasci che ruota attorno a tre numeri: major, minor e patch.
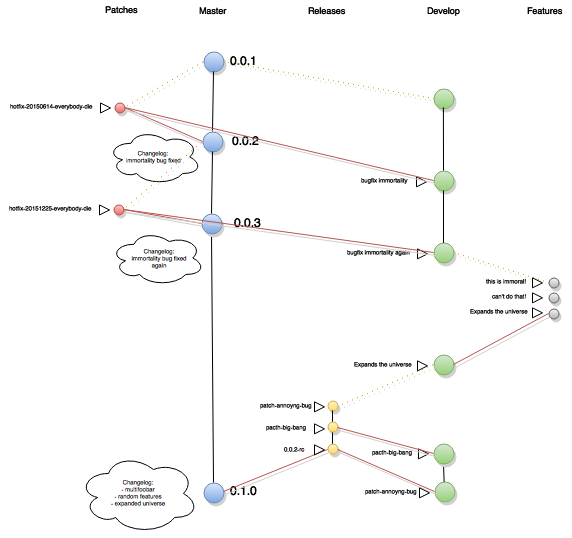
Il formato prevede la concatenazione di questi tre numeri attraverso la notazione punto. Ad es: 1.1.2, indica major version: 1, minor version: 1 e patch: 2.
Riportato sullo schema prima descritto nel GIT flow, i tre numeri di versionamento saranno le tag dei branch.
In pratica:
- Se abbiamo rilasciato una hotfix, che sostanzialmente non va ad intaccare le modalità di utilizzo del codice, dovremmo andare a incrementare il numero di patch.
- Se abbiamo implementato una modifica minore, spesso l’aggiunta di una feature che non pregiudica la retrocompatibilità del codice, andremo a incrementare il numero di minor versioning.
- Rilasci più consistenti che cambiano in maniera apprezzabile il funzionamento del codice andranno a incrementare il numero di major versioning
Può essere inoltre indicato un suffisso di build, ad esempio una sequenza alfabetica in linguaggio naturale, seguita da un numero incrementale.
Ad es:
- 1.1.2-snapshot20150602, indica una snapshot di un feature branch di 1.1.2, ovvero una “fotografia” specifica dello sviluppo di una feature
- 1.1.2-rc1, indica una release candidate, ovvero una versione del software “papabile” per il rilascio
Un suffisso di build come quello indicato nel primo esempio potrebbe essere relativo ad un feature branch, derivato dal tag 1.1.2 del branch di sviluppo e in parole povere indica che quella messa a disposizione è semplicemente un’anteprima del codice, in cui è ammissibile una certa instabilità.
Questo tipo di tag dovrebbero essere provati e installati solo su ambienti di test.
Quello nel secondo esempio invece potrebbe essere il suffisso di un tag su un branch di release che indica una versione del codice, matura al punto da poter essere inclusa in una prossima release, detta release candidate, a patto di minime correzioni. Tali modifiche modifiche e correzioni dovrebbero susseguirsi andando a incrementare il suffisso numerico dopo rc delle prossime tag sul ramo di rilascio.
Questo tipo di tag indicano le versioni del software che generalmente verranno installate sugli ambienti di staging, per poterle testare prima di essere riportate su master e andare quindi in produzione.
Conclusioni
Alla fine di questa analisi non possiamo affermare che git flow e il versionamento semantico possano essere gli strumenti definitivi per ogni team o progetto, e sicuramente la loro adozione porta vantaggi e svantaggi. Valutare un trade-off relativo all’impiego di git flow sta al buonsenso personale, ci limiteremo perciò ad elencare una serie di pro e contro che potrebbero aiutare nella decisione.
A cosa non serve git flow?
- Git flow non pone rimedio ad errori tecnici nella gestione del repository e nemmeno prescinde da una conoscenza approfondita di git.
- Git flow de facto non semplifica il flusso di lavoro con git, imponendo una strategia di diramazione complessa.
A cosa serve git flow?
- Git flow aiuta i vari elementi del team ad avere a colpo d’occhio una visione precisa dello stato degli sviluppi applicativi a fronte di una convenzione essenziale e immediata di tagging.
- Il versionamento semantico aiuta gli utilizzatori del software a capire esattamente lo stato di sviluppo del software e cosa aspettarsi, riportandosi a diverse versioni di rilascio.
- Git flow coaudiva la velocity del team di sviluppo permettendo l’attuazione di un piano di continuous deploy e quindi di poter rilasciare nuove feature e fix in sicurezza.
- Git flow è ottimo per la continuous integration, permettendo de facto di poter differenziare i rami dedicati ai vari ambienti: sviluppo, staging e produzione
Risorse consultabili online
- http://nvie.com/posts/a-successful-git-branching-model/ Vincent Driessen espone GIT Flow
- http://semver.org/ Semantic Versioning 2.0.0 proposto da Tom Preston-Werner
- https://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow - Tutorial messo a disposizione da Atlassian
- https://datasift.github.io/gitflow/Versioning.html

Share this post
X
Facebook
Reddit
LinkedIn
StumbleUpon
Pinterest
Email