
14 minute read
Introduction
During these months at Facile.it I had to face many challenges regarding the improvement of CI/CD pipelines for the Insurance team, with a strong focus on performance and reusability. The focus on these topics is very important as it allows us to follow GitLab best practices for CI/CD such as the fail fast principle.
💬
Fail fast: On the CI side, devs committing code need to know as quickly as possible if there are issues so they can roll the code back and fix it while it’s fresh in their minds. The idea of “fail fast” helps reduce developer context switching too, which makes for happier DevOps professionals.
Following this post from 2018, my team ended up having a CI/CD pipeline that fully relied on Docker Compose for every job besides the deployment ones.
Using Docker Compose has many advantages, mainly because it allows developers to use the very same configuration for both their local setups and the CI/CD jobs (e.g. environment variables and services). However, this comes with something that I believe to be a major drawback: the job execution time using Docker Compose is less than ideal, this makes our pipelines a few times slower than an equivalent solution that does not use it!
This blog post is not meant as a comparison between Docker Compose and other alternatives, so I will not dive deep into the numbers and details. However, given the focus on performance I mentioned above, I decided to tackle this issue and move from Docker Compose to a more “native” solution.
Anatomy of our project
Scope and goals
To better understand what made the transition from Docker Compose way harder than I expected, we need to provide a brief overview on the project’s structure and how the application that we’re building is supposed to work.
The main idea behind this application, which we will call ins-gateway from now on, is to act as a kind of gateway between our core services and multiple insurance companies. We can see it as an abstraction layer that is used to standardize both requests and responses so that we can convert them into our custom format. This layer is required since each company may have a specific communication protocol/format.
Having to deal with a large amount of different protocols/formats makes everything error-prone: what if a certain company decides that a property is now a number instead of a string but they fail to let us know that their specifications changed?
We can’t to project errors onto the end user because of such a small change, so we need a better way to be somehow proactive and intercept those changes before they reach our production systems.
That’s why we have a set of multiple tests running in our CI/CD environment that help us keep everything under control. In this post, we’re only going to focus only on unit tests.
Unit tests and Docker Compose
In DevOps world, unit tests can be seen as an automated way to do regression testing, meaning that we can use them to guarantee that our new commit didn’t break an already working feature.
This is extremely useful for projects that are starting to outgrow the resources of the dedicated team and would require significant effort to manually verify everything before committing.
In our scenario, this means that we defined these unit tests to validate the format of the request/response pair for each insurance company, thus being able to quickly react to their changes.
However, since unit tests are not meant to depend on external systems, we decided to build another layer: mock servers.
Here’s a quick diagram showing a simplified version of our testing process that includes only two companies:
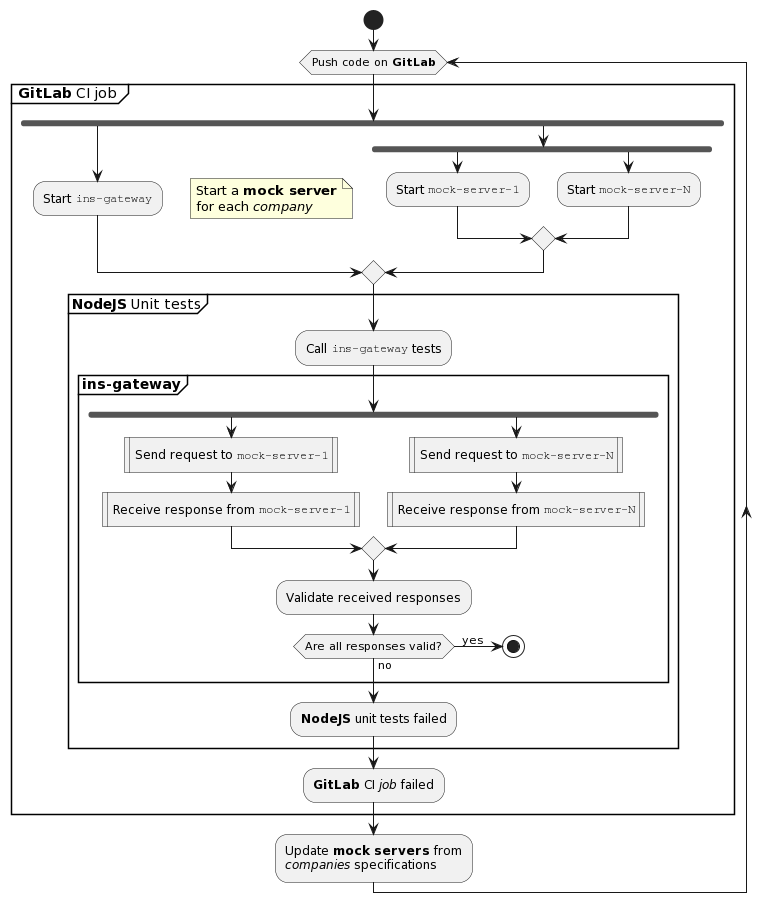
While this is a simplified version of the process, the important thing to notice is that we have a single mock server even though we deal with two companies!
To avoid dealing with multiple codebases, we decided to build a generic mock server that is configured at runtime with the specific protocol/format used by a given company. This configuration is done through the environment variables.
If you’re not already seeing the issue here, allow me to introduce Docker Compose in the current scenario by showing some of the contents of our old docker-compose.yaml file:
version: '3.7'
services:
...
mock-company-1:
image: $MOCK_IMAGE:$COMMIT_ID
env_file:
- ./company-1/default.env
mock-company-2:
image: $MOCK_IMAGE:$COMMIT_ID
env_file:
- ./company-2/default.env
As you can see, in the docker-compose.yaml file we defined two different services with the very same Docker image and different env_files to provide the specific configuration.
⚠️
The
env_filecontains the very sameenvironment variablesfor both theservicesbut with different values, and this is the root cause of the issue that I had to solve while moving away from Docker Compose!This is a quick sample of an
env_filefor our mock serversAPP_PORT=3000 COMPANY_NAME=... PROTOCOL_VERSION=...
This works because of how Docker Compose works: each service has its own “context” and a set of environment variables that are not shared with other services, which means there is no name collision.
But what happens if we replace Docker Compose with GitLab’s “native” services? Well, that’s a completely different story.
Moving away from Docker Compose
GitLab’s services and their relation with Docker Compose
GitLab’s services are a clever way to provide additional capabilities to your CI/CD job. These capabilities are usually external dependencies such as a database, or even a docker-in-docker helper that enables building Docker images from a running Docker container.
ℹ️
If you want to know more about GitLab’s
services, their documentation is a great starting point.
Given their nature, GitLab’s services can naturally be mapped from those of Docker Compose, or at least that’s what I thought when I started this task.
Just like in Docker Compose, GitLab’s services are defined as:
name: # Docker image to be used as service
alias: # optional hostname for your service in the internal networking
entrypoint: # optional override for the Docker entrypoint
command: # optional ovveride for the Docker entrypoint
But…isn’t something missing from what we had in our docker-compose.yaml file?
The answer is yes: before GitLab 14.8, services couldn’t specify a set of custom environment variables (as reported in issue #23671 on GitLab).
ℹ️
This change is not mentioned in the 14.8 release notes because it’s been split over multiple releases, but you can refer to both GitLab 14.5 changelog and GitLab Runner 14.8 changelog
So, how are we supposed to add environment variables to our GitLab’s services?
GitLab jobs support the variables property which allows us to define a set of environment variables as a YAML hash, and services inherit all the variables defined in their parent job.
Let’s make a quick example of what this means:
job-1:
variables:
VAR: Job variable # This is meant as a variable to be used in job's script
SVC_VAR: Service variable # This is meant as a variable to be used EXCLUSIVELY by the service
services:
- name: busybox:latest # Use a simple Busybox image so that we can a shell and just echo some variables
entrypoint: [ "sh", "-c", "echo $VAR, $SVC_VAR" ]
script:
- ...
Upon service startup the entrypoint is executed, leading to the following output:
2022-04-04T12:56:48.722815200Z Job variable, Service variable
ℹ️
serviceoutput is printed at the beginning of yourjob’s output on GitLab. Additionaly, it can be extracted from Docker or Kubernetes container logs based on where your GitLab Runner is installed.
While this seems to work correctly, we have to remind about the warning that I mentioned in the previous chapter: we’re using a single mock server which is configured using a set of environment variables. Therefore, each instance of the mock server requires exactly the same variables.
Following from the previous example, let’s move to something closer to our scenario by tanslating the docker-compose.yaml file into a .gitlab-ci.yml one:
job-1:
services:
- name: $MOCK_IMAGE:$COMMIT_ID
alias: company-1-mock
- name: $MOCK_IMAGE:$COMMIT_ID
alias: company-2-mock
script:
- npm run tests # Generic wrapper to test all the companies
variables:
COMPANY_NAME: company-1 ⚠️
COMPANY_NAME: company-2 ⚠️
...
Hold on!
If both company-1-mock and company-2-mock use the same COMPANY_NAME variable, how can we pass the value company-1 to company-1-mock and company-2 to company-2-mock?
Well, we can’t, and that’s because environment variables are passed at job level and shared with all the linked services. The above snippet will still work, but both the mock servers will receive the latest value set for each variable, so they will both initialized with COMPANY_NAME = company-2, which is not what we want.
A first workaround
Once getting to this issue I quickly realized that the task was about to get way more complicated than what I thought, because I got to a point where I was limited by the lack of a feature on GitLab.
I’m not a developer anymore and I never had the chance to work with Ruby (which is the main backend language for GitLab), so I didn’t feel confident enough to try and see if I could solve this by myself.
I decided to implement an “hacky” workaround that allowed my CI/CD pipeline to move away from Docker Compose while still keeping the ability to use multiple instances of the same GitLab service.
The workaround revolves around a fairly simple idea: as we have seen before, GitLab services support the override of both the entrypoint and command of the Docker image. This can be used to provide additional logic that must be executed when the image is started.
This fact, coupled with the variables shared between jobs and services, enabled me to provide some kind of “scoped” variables to each mock server instance in the following way:
job-1:
services:
- name: $MOCK_IMAGE:$COMMIT_ID
alias: company-1-mock
entrypoint: ["/bin/sh"]
command: ["-c", "echo \"$COMPANY_1_ENVIRONMENT\" > init.env && source init.env; <original Docker command>"]
- name: $MOCK_IMAGE:$COMMIT_ID
alias: company-2-mock
entrypoint: ["/bin/sh"]
command: ["-c", "echo \"$COMPANY_2_ENVIRONMENT\" > init.env && source init.env; <original Docker command>"]
script:
- npm run tests # Generic wrapper to test all the companies
variables:
COMPANY_1_ENVIRONMENT: |
export COMPANY_NAME=company-1
export OTHER_VAR=...
COMPANY_2_ENVIRONMENT: |
export COMPANY_NAME=company-2
export OTHER_VAR=...
...
Success, it works! ✅
We basically replaced the startup process for each of our services to load the variables from a local file, and each service has a different file. This works a bit like the env_file directive in the docker-compose.yaml file we have seen above.
⚠️ However, since this is a workaround, there are some implications that need to be considered:
- We can’t define the
variablesas plainYAMLproperties as we did with Docker Compose. - We still need to define a shared
variablefor eachserviceatjoblevel, meaning thatcompany-2-mockcan doecho $COMPANY_1_ENVIRONMENTand retrieve all the values for the other mock server, thus breaking the isolation betweenservices. - We need to manually add the original Docker
commandat the end of our overriden one, meaning that we need to keep it updated in case the base Docker image changes.
To overcome these issues we need a less “hacky” way to deal with our scenario, even if GitLab is not supporting it. Luckily, GitLab is opensource software and this allows people to contribute to their codebase even if they are not directly employed by GitLab itself.
As I said before I’m not a developer anymore, but I decided to go ahead and took my chance at adding the feature that we needed to improve our CI/CD pipelines.
Becoming a GitLab contributor to solve our issue with CI/CD
ℹ️
To develop on GitLab’s platform you need the GitLab Development Kit. The kit is well documented so I won’t go into the details of the workflow.
If you’re not familiar with GitLab’s codebase, the initial experience will be daunting at best, as their repository is quite large. Furthermore, the lack of experience with Ruby didn’t help, but eventually I got a grip on which classes I needed to fiddle with to make my feature work.
The feature proposal was to extend services definition by adding the same variable property that was already available for jobs, so that the validation logic and variables handling could be reused.
This is the proposed structure, following the previous examples:
job-1:
variables:
VAR: Job variable # This is meant as a variable to be used in job's script
services:
- name: busybox:latest # Use a simple Busybox image so that we can a shell and just echo some variables
variables:
SVC_VAR: Service variable # This is meant as a variable to be used EXCLUSIVELY by the service
entrypoint: [ "sh", "-c", "echo $VAR, $SVC_VAR" ]
script:
- echo $VAR, $SVC_VAR
As you can see, SVC_VAR was now moved as a child of the service definition, meaning that it’s not shared at the job level as before.
Implementing this was easier than I thought, as I only had to copy the variables keyword from the job definitions (e.g. endpoints and internal data models) to their service counterparts. Considering these changes, GitLab documentation, and some unit testing I only had 20 lines added and 5 removed.
ℹ️
The complete history of my changes is tracked in the merge request #72025 on GitLab.
However, this small merge request was not enough, as services are handled differently by each underlying provider (Docker and Kubernetes). These providers are implemented by the GitLab Runner project, which provides an executable that’s responsible for getting and executing jobs from a registered GitLab instance.
This means that I had to add a specific logic to both the providers so that they could correctly deal with the new variables property defined in the service object.
While the changes on GitLab itself weren’t really challenging, the way GitLab Runner handles environment variables made everything a lot more difficult. Without diving deep into details, GitLab Runner is responsible for variables expansion at shell level, so this new feature must not break the existing workflow.
The issue is better explained by Arran Walker, who reviewed my merge request:
💬
My main concern was that we want a service’s variables expanded when they reference a variable that is available to the main job too.
For example:
variables: TOP_LEVEL_VAR: "hello" job: variables: JOB_LEVEL_VAR: "world" service: - image: docker:dind variables: SERVICE_LEVEL_VAR: "$TOP_LEVEL_VAR $JOB_LEVEL_VAR"
SERVICE_LEVEL_VARshould be able to referenceTOP_LEVEL_VARandJOB_LEVEL_VAR. Expanding the service variables on their own won’t achieve this.– https://gitlab.com/gitlab-org/gitlab-runner/-/merge_requests/3158#note_740206844
After a few months of back and forth with the GitLab Runner team, we ended up finding a solution that enabled my use case while still retaining the correct variable expansion logic, as nobody wanted to introduce a breaking-change on such a big platform.
ℹ️
The complete history of my changes is tracked in the merge request #3158 on GitLab Runner.
My contributions were merged to GitLab with version 14.5 and to GitLab Runner with version 14.8, making me a contributor to their platform!

Our final CI/CD pipeline
At the end of this process, we were finally able to move away from Docker Compose while still having a CI/CD pipeline that didn’t need any workarounds or hacks to be fully functioning. With GitLab 14.8, our sample pipeline can now be modified as follows:
job-1:
services:
- name: $MOCK_IMAGE:$COMMIT_ID
alias: company-1-mock
variables:
COMPANY_NAME: company-1
OTHER_VAR: ...
- name: $MOCK_IMAGE:$COMMIT_ID
alias: company-2-mock
variables:
COMPANY_NAME: company-1
OTHER_VAR: ...
script:
- npm run tests # Generic wrapper to test all the companies
If we consider the issues mentioned in our first workaround, we can see that with this solution we were able to fix them all:
We can’t define thevariablesas plainYAMLproperties as we did with Docker Composevariablesare now defined as plainYAMLproperties.✅We still need to define a sharedvariablefor eachserviceatjoblevel, meaning thatcompany-2-mockcan doecho $COMPANY_1_ENVIRONMENTand retrieve all the values for the other mock server, thus breaking the isolation betweenservicesvariablesare now defined on aservicebasis, thus they’re not shared anymore.✅We need to manually add the original Dockerwe don’t need to override thecommandat the end of our overriden one, meaning that we need to keep it updated in case the base Docker image changesentrypointandcommandfor theserviceDocker image.✅
Conclusions
The goal of this post was to show how a problem in daily tasks, coupled with a winning opensource culture, can be turned into an opportunity to grow as a professional and become a contributor to one of the largest DevOps platforms in the world. We’re usually somehow “limited” by our tools when it comes to problems, and that means we’re somehow forced to find “hacky” workarounds to overcome them. However, by relying on widely supported opensource software, not only can we easily find a better solution to our problems, but we also have the opportunity to become part of the movement that enables our daily tasks as IT professionals.
(finally, as a side note, being a GitLab contributor has some small perks too!)


Share this post
X
Facebook
Reddit
LinkedIn
StumbleUpon
Pinterest
Email